Transformer Neural Network Example
Quantum-enhanced transformer neural network. This post are notes to understand sequence-to-sequence s2s neural networks and in particular the Transformer neural network architecture and training.
Use Transformer Neural Nets New In Wolfram Language 12
Apr 24 2020 13 min read.

Transformer neural network example. The Transformer neural network architecture EXPLAINED. There is also research and development under way to apply them to additional areas such as image recognition. It extends concepts introduced in this post.
This example demonstrates transformer neural nets GPT and BERT and shows how they can be used to create a custom sentiment analysis model. Scope of Token Relations - using a recurrent mechanism one token such as a word can be related to only a. Most applications of transformer neural networks are in the area of natural language processing.
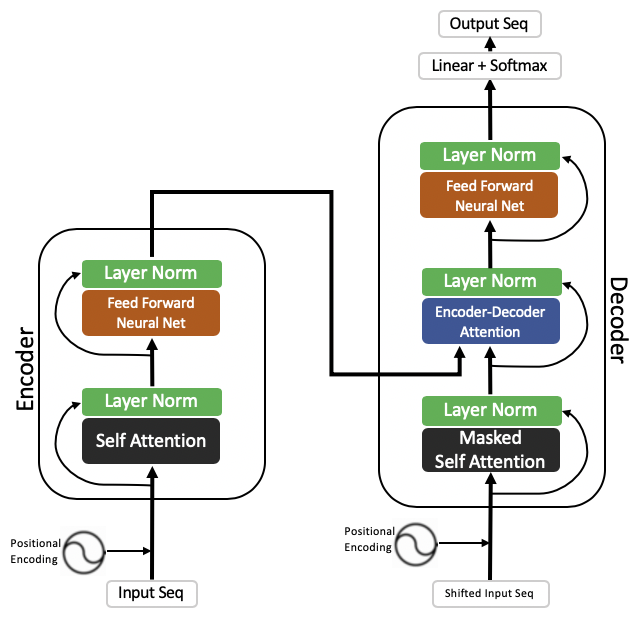
Neural translation with attention. Neural networks for machine translation typically contain an encoder reading the input sentence and generating a representation of it. It replaces earlier approaches of LSTM s or CNN s that used attention between encoder and decoder.
Contribute to rdisipioqtransformer development by creating an account on GitHub. This is a tutorial on training a sequence-to-sequence model that uses the nnTransformer module. The biggest benefit however comes from how The Transformer lends itself to parallelization.
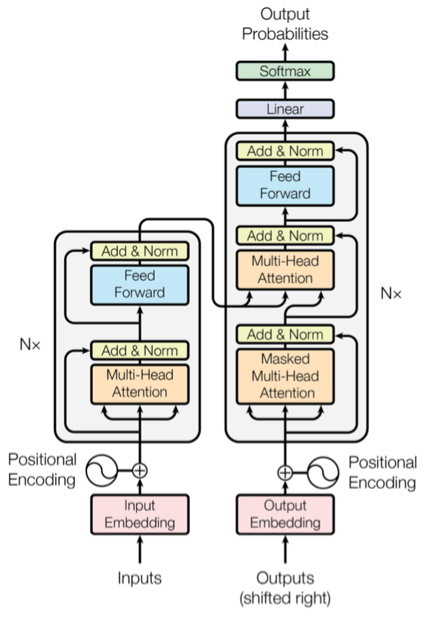
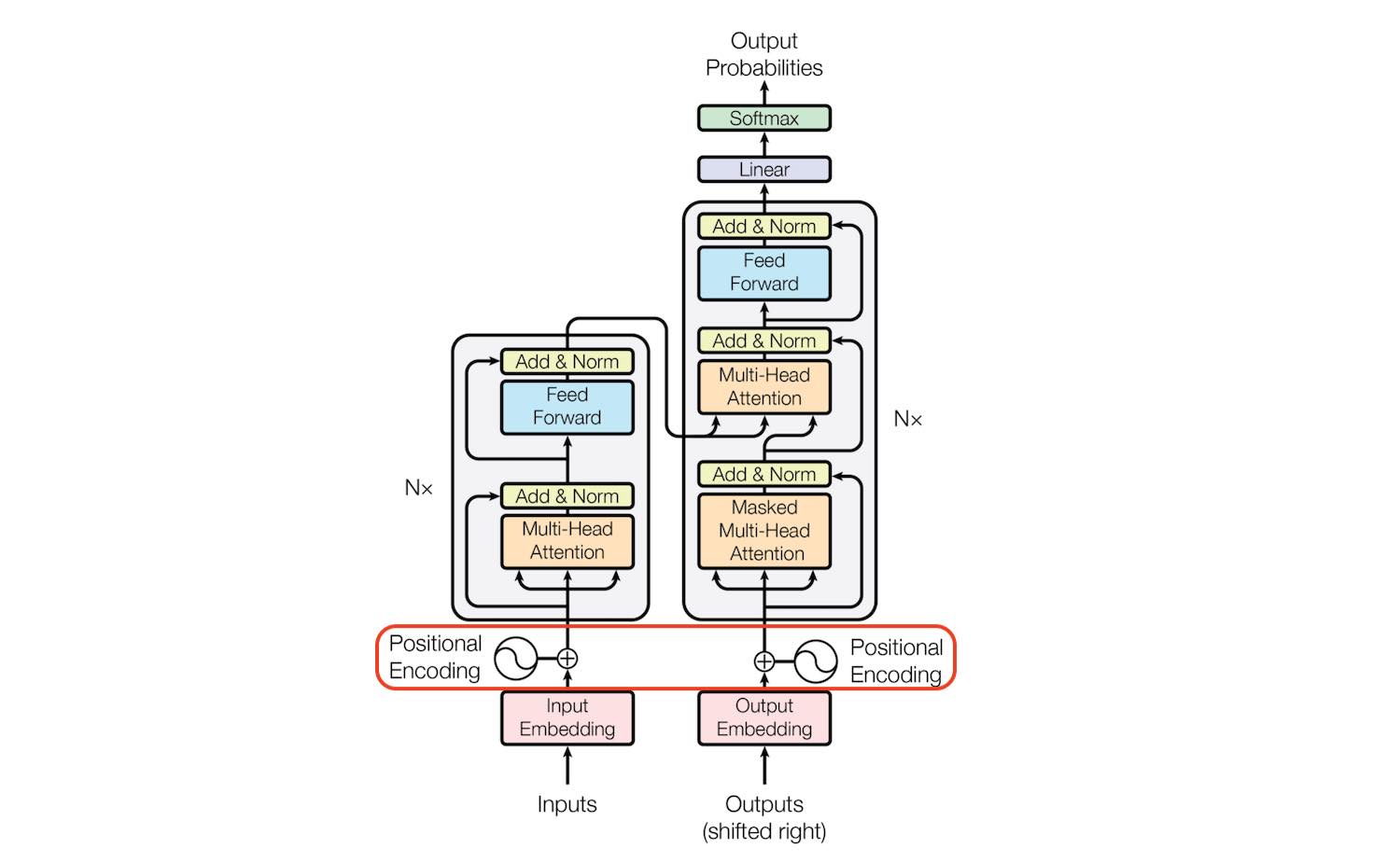
It was proposed in the paper Attention Is All You Need 2017 1. The Transformer starts by generating initial representations or embeddings for each word. The transformer is a component used in many neural network designs for processing sequential data such as natural language text genome sequences sound signals or time series data.
Complementary to other neural architectures like convolutional neural networks and recurrent neural networks the transformer architecture brings new capability to machine learning. Transformer as a Graph Neural Network. Attention is all you need NLP - YouTube.
Sequence-to-Sequence or Seq2Seq is a neural net that transforms a given sequence of elements such as the sequence of words in a sentence into another sequence. The Transformers outperforms the Google Neural Machine Translation model in specific tasks. First we should go back to the origin of neural translation.
The Transformer Neural Network is a novel architecture that aims to solve sequence-to-sequence tasks while handling long-range dependencies with ease. Language Modeling with nnTransformer and TorchText. Transformer Neural Networks are non-recurrent models used for processing sequential data such as text.
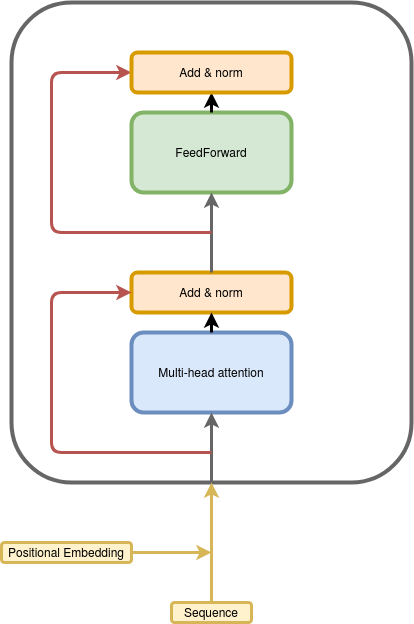
Transformer showed that a feed-forward network used with self-attention is sufficient. Create classifier model using transformer layer. In Out.
Here we take the mean across all time steps and use a feed forward network on top of it to classify text. A decoder then generates the output sentence word by word while consulting the representation generated by the encoder. Universal Transformer is an example to show how update_graph adapts to more complex updating rules.
So lets try to break the model apart and look at how it functions. The Universal Transformer was proposed to address the problem that vanilla Transformer is not computationally universal by introducing recurrence in Transformer. A transformer is a new type of neural network architecture that has started to catch fire owing to the improvements in efficiency and accuracy it brings to tasks like natural language processing.
The PyTorch 12 release includes a standard transformer module based on the paper Attention is All You NeedCompared to Recurrent Neural Networks RNNs the transformer model has proven to be superior in quality for many sequence-to. Transformer layer outputs one vector for each time step of our input sequence. It is in fact Google Clouds recommendation to use The Transformer as a reference model to use their Cloud TPU offering.
Key aspects of Transformers include. Transformer is a neural network architecture that makes use of self-attention. The Transformer neural network architecture EXPLAINED.
Embed_dim 32 Embedding size for each token num_heads 2 Number of attention heads ff_dim 32 Hidden layer. Load the GPT and BERT models from the Neural Net Repository.
Transformer Attention Is All You Need By Pranay Dugar Towards Data Science
Music Genre Classification Transformers Vs Recurrent Neural Networks By Youness Mansar Towards Data Science
Transformer 1 2 Pytorch S Nn Transformer
Transformer Architecture The Positional Encoding Amirhossein Kazemnejad S Blog
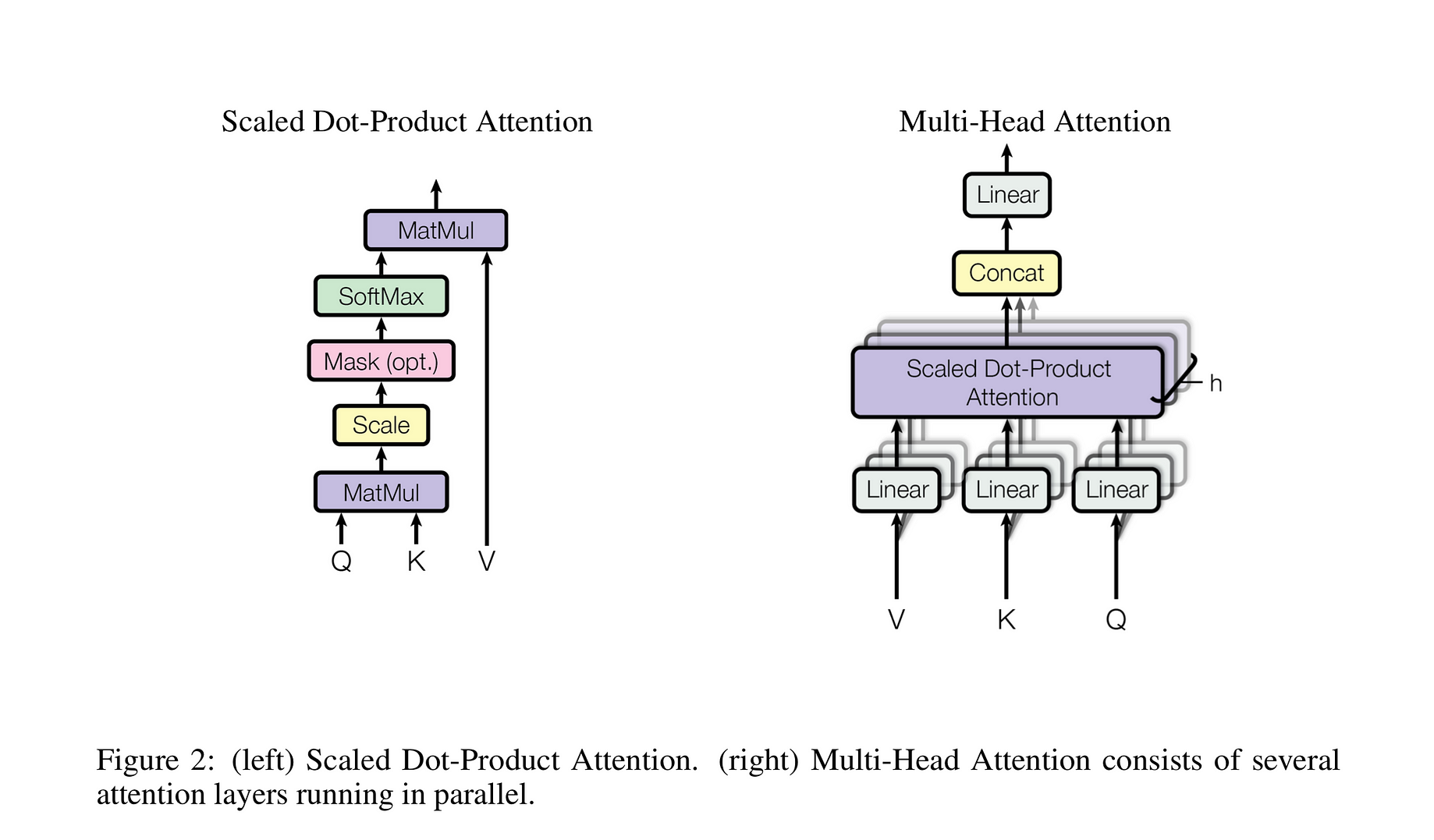
What Is A Transformer An Introduction To Transformers And By Maxime Inside Machine Learning Medium
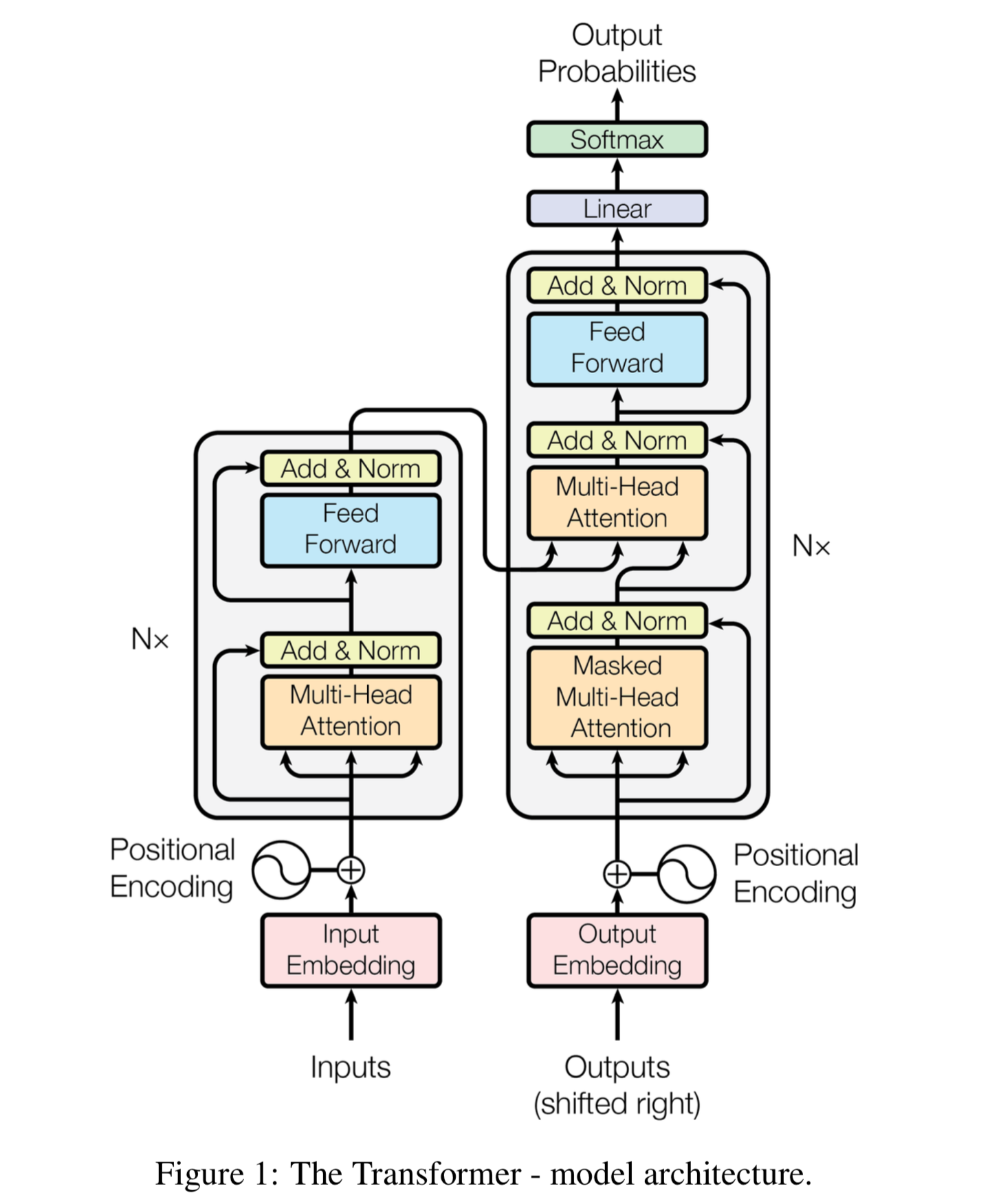
Use Transformer Neural Nets New In Wolfram Language 12
Transformer Xl Explained Combining Transformers And Rnns Into A State Of The Art Language Model By Rani Horev Towards Data Science

Transformer Explained Papers With Code
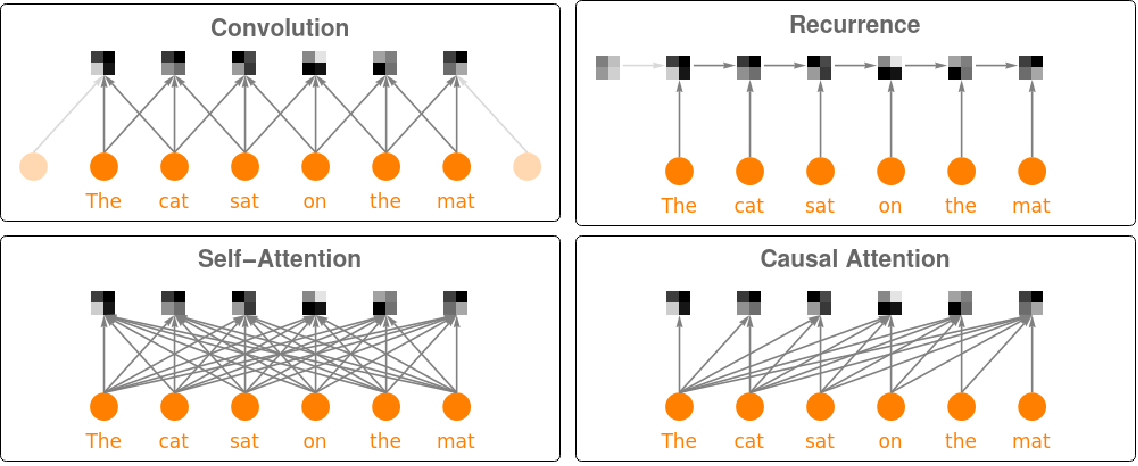
What Is A Transformer An Introduction To Transformers And By Maxime Inside Machine Learning Medium

Transformer Neural Network Definition Deepai
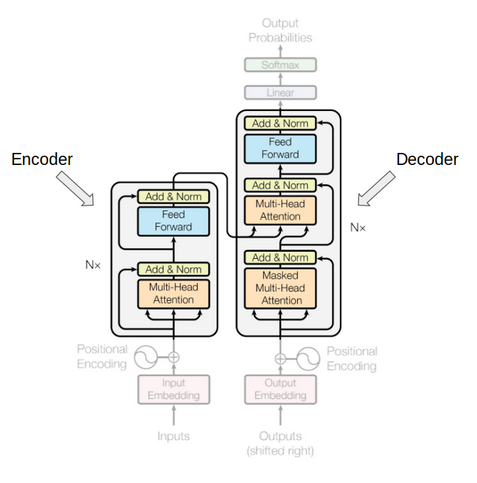
Transformers In Natural Language Processing A Brief Survey Eigenfoo
![]()
Transformer Neural Network Definition Deepai
Github Lilianweng Transformer Tensorflow Implementation Of Transformer Model In Tensorflow
![]()
9 3 Transformer Dive Into Deep Learning 0 7 Documentation
![]()
Bilstm Based Nmt Architecture 2 Transformer Self Attention Based Download Scientific Diagram
![]()
Radio Transformer Network Architecture Download Scientific Diagram

Transformer Neural Network Architecture

Transformer Architecture Self Attention Kaggle
The Evolved Transformer Enhancing Transformer With Neural Architecture Search By Rani Horev Towards Data Science
0 Response to "Transformer Neural Network Example"
Posting Komentar